on
Systems Architecture of A Scale: Intro
The untold truth for any software test engineer is that you need to pick up system architecture under test on the go by working through the pain of a growing product or working with engineers who have previously learned through that suffering process and are willing to help.
Wait, I’m a Software Test Engineer. Why do I need this?
It can be challenging for someone who has not tested scalable systems to understand the different components involved in building scalable applications. Personally, I didn’t know anything about infrastructure concepts (much of it was based on AWS) before I started working on an IaaS (Infrastructure as a Service) product.
I will attempt to cover a bit of the systems scalability architectures in a simplified way! I will also reference some infrastructure services by AWS.
1. Load Balancing
Load Balancer is an essential component of any distributed system which lies between a client and a server. It accepts incoming requests and routes them across a cluster of servers to handle the load. It tracks the health status of all the servers connected. If a particular server is unhealthy (aka down), it will not send incoming requests to that server. We will call this horizontal scalability
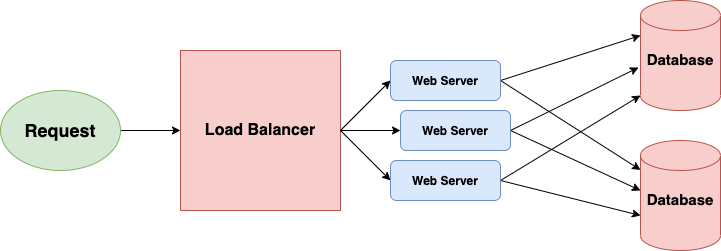
But what happens when a server is down in a load balancer? 🤔
A perfect system shouldn’t be interrupted by the failure of a server. A falling server should solely reduce system capacity by the same amount it raised overall capacity when it was added. We will call this redundancy.
TL;DR both horizontal scalability and redundancy are usually achieved via load balancing.
2. Systems Caching
Say you’re managing a cooking application with lots of recipes. As with any application, you want to serve up pages as fast as possible.
When a user requests a recipe, you get the corresponding file from a database, read it, and transfer it back over the web. This works, but it’s much slow since accessing the database takes a while. Ideally, if lots of users inquire about the same recipe, you’d want to only read it from the database once, keeping the page in memory so you can quickly send it out again when it’s requested. Voila. You just added a cache.
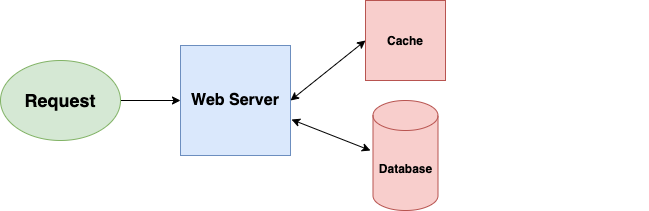
A cache is a just fast storage. Reading data from a cache takes less time than reading it from something else (like a hard disk).
TL;DR caching allows you to optimize the resources you already have. It consists of precalculating events and reduces overheads, pre-generating expensive indexes, and saving copies of regularly accessed data in a faster backend.
There are two fundamental approaches to caching: application caching and database caching. Application caching works by verifying if the data requested is in the cache. If that’s not the case, It will get the database’s data and then write the value into the cache. (ElastiCache, Memcached, and Redis are examples of in-memory caches).
3. Content Distribution Networks
A special kind of cache that comes into action for applications serving considerable static media volumes is the content distribution network. CDNs carry the responsibility of serving static media off your application servers (which are typically optimized for serving dynamic pages rather than static media) and provide geographic distribution.
TL;DR Your static assets will load more quickly and with less pull on your servers (but a new pull of business expense).
What happens under the hood? 🤨
A request will first ask your CDN for a piece of static media; the CDN will serve that content if it has it locally available. If it isn’t available, the CDN will query your servers for the file and then cache it locally and serve it to the requesting user (in this configuration, they act as a read-through cache).
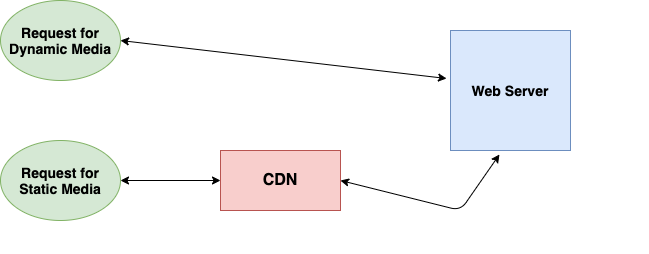
4. Message Queues
Let’s say you are at a local pizza restaurant and want to order some food from the cashier. It’s an up and coming pizza restaurant, there is only one cashier. A cashier can get an order from one person to process at a given time. In this case, what do you do when you see there’s a person already who is ordering? Do you wait in a queue or go back with an empty stomach? Exactly! You wait in a queue until your turn comes.
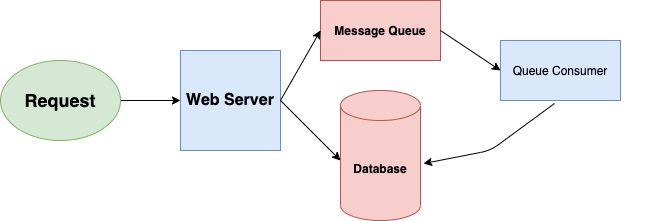
This is one real-world example of queues , and message queues serve the same purpose in any software architecture.
TL;DR Message queues allow your web applications to quickly publish messages to the queue and have other consumer processes perform the processing outside the client request’s scope and timeline.
Dividing work between offline work handled by a consumer and in-line work done by the web application depends entirely on implementation. Generally, you’ll either:
- perform almost no work in the consumer (scheduling a task) and inform your user that the task will occur offline or,
- perform enough work in-line to make it appear to the user that the task has been completed, and tie up loose ends afterward (posting a message on Twitter or Instagram likely follow this pattern by updating the tweet/photo in your timeline).
AWS SQS and Kafka are some of the popular message queuing services available.
5. Scheduling Periodic Tasks
Most large systems require daily or hourly tasks. You have probably heard of cron. You could use the cronjobs to publish messages to a consumer, which would mean that the crown machine is only responsible for scheduling rather than needing to perform all the processing.